Distributed Training Concepts#
How Determined Distributed Training Works#
Determined employs data or model parallelism in its approach to distributed training. Data parallelism for deep learning consists of a set of workers, where each worker is assigned to a unique compute accelerator such as a GPU or a TPU. Each worker maintains a copy of the model parameters (weights that are being trained), which is synchronized across all the workers at the start of training.
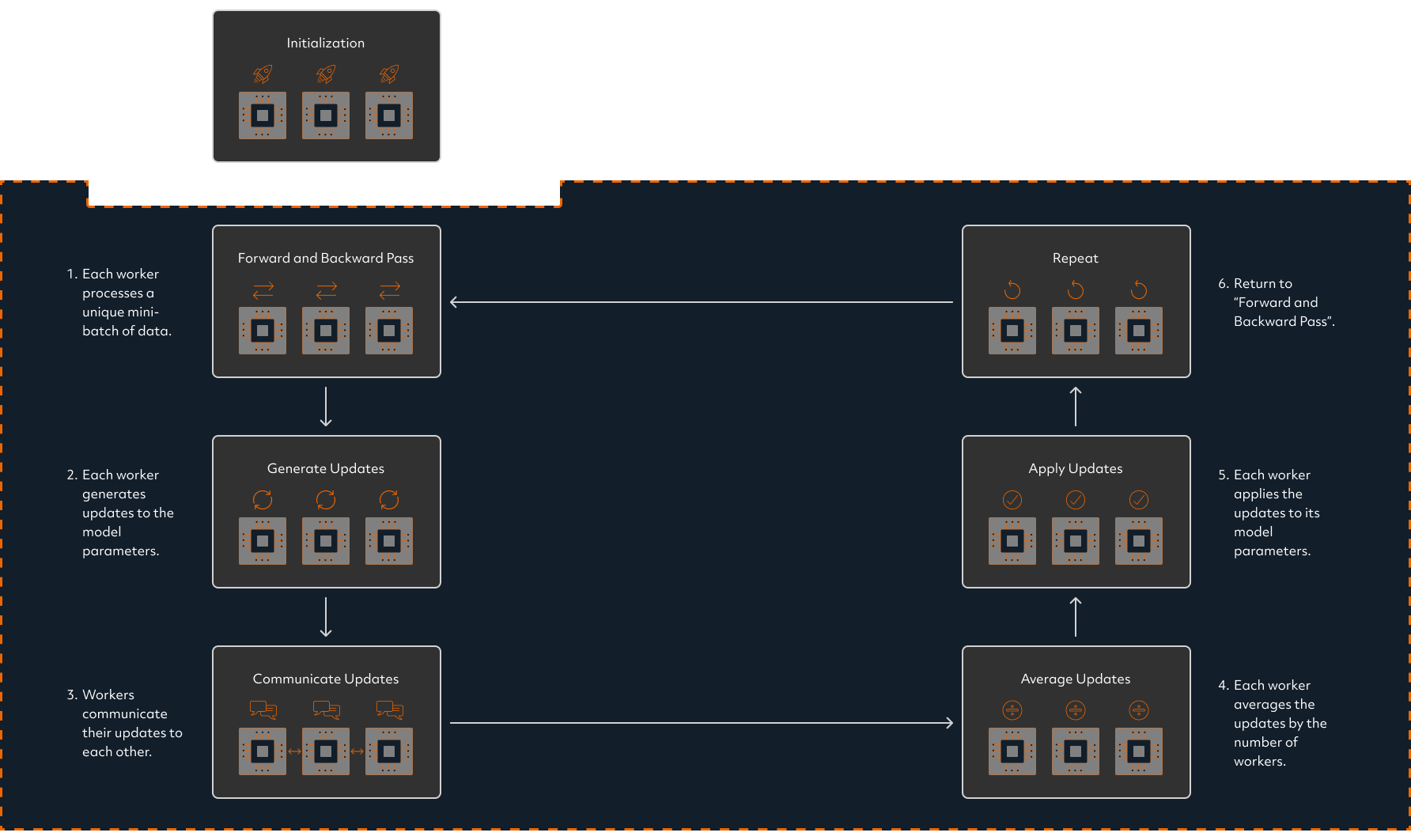
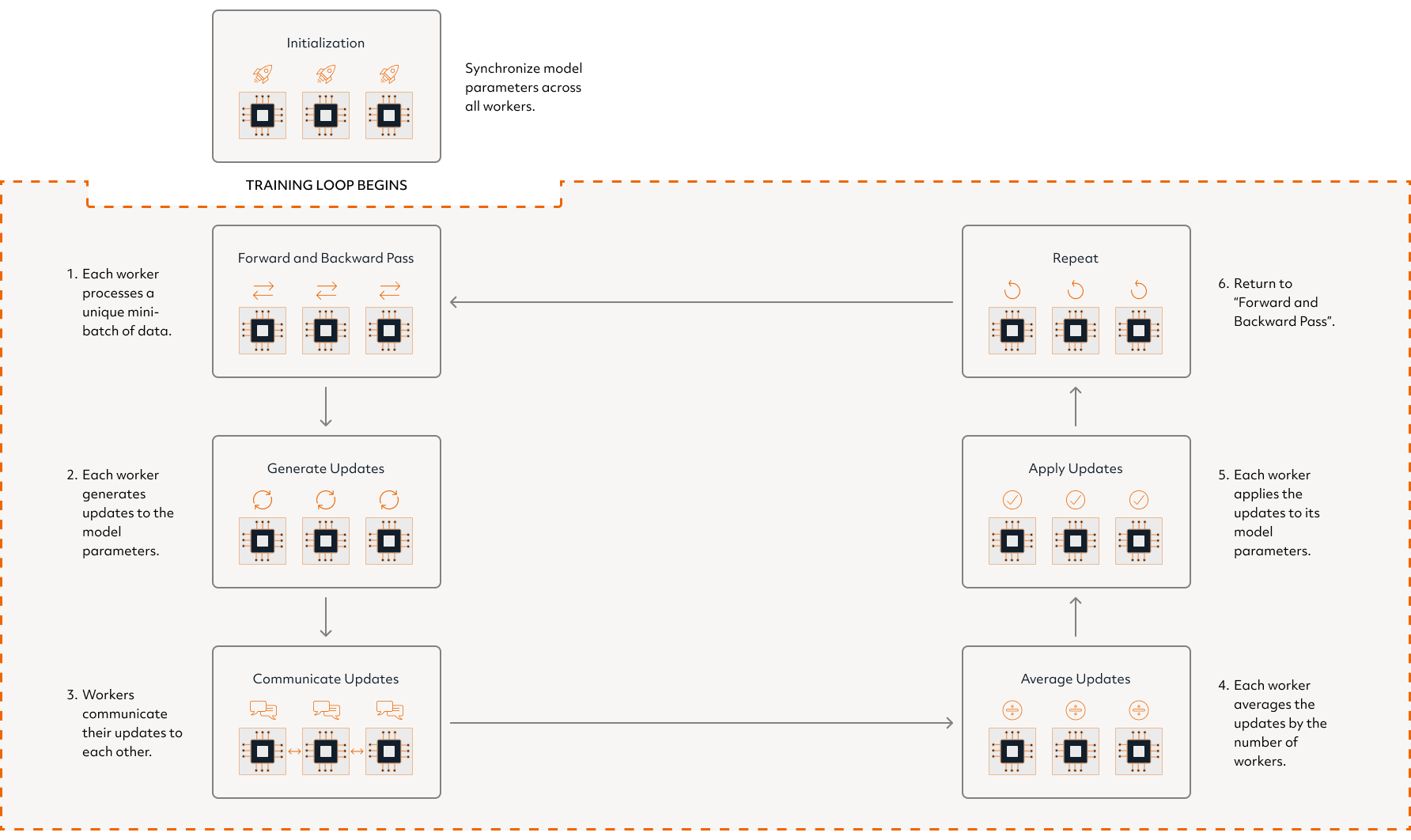
Determined AI Distributed Training Loop
After initialization is completed, distributed training in Determined follows a loop where:
Every worker performs a forward and backward pass on a unique mini-batch of data.
As a result of the backward pass, every worker generates a set of updates to the model parameters based on the data it processed.
The workers communicate their updates to each other so that all the workers see all the updates made during that batch.
Every worker averages the updates by the number of workers.
Every worker applies the updates to its copy of the model parameters, resulting in all the workers having identical solution states.
Return to the first step.
Performance Optimization#
Reducing Computation and Communication Overhead#
The first two steps of the training loop (forward and backward pass + generate updates) incur the most computational overhead. To reduce this computational overhead, we recommend using the GPU to its maximimum capacity. This can be accomplished by using the largest possible batch size that fits into memory.
To achieve this, set the global_batch_size to the largest batch size that fits into a single GPU
multiplied by the number of slots. This approach is commonly known as weak scaling.
The third step of Determined’s distributed training loop incurs the majority of the communication
overhead. Since deep learning models typically perform dense updates, where every model parameter is
updated for every training sample, batch_size does not affect how long it takes workers to
communicate updates. However, increasing global_batch_size does reduce the required number of
passes through the training loop, thus reducing the total communication overhead.
Determined optimizes the communication in the third step by using an efficient form of ring all-reduce, which minimizes the amount of communication necessary for all the workers to communicate their updates. Furthermore, Determined reduces the communication overhead by overlapping computation (steps 1 & 2) and communication (step 3) by communicating updates for deeper layers concurrently with computing updates for the shallower layers. Visit Advanced Optimizations for additional optimizations for reducing the communication overhead.
Debugging Performance Bottlenecks#
Scaling up distributed training from one machine to two machines may result in non-linear speedup
because intra-machine communication (e.g., NVLink) is often significantly faster than inter-machine
communication. Scaling up beyond two machines often provides close to linear speed-up, but it does
vary depending on the model characteristics. If observing unexpected scaling performance, assuming
you have scaled your global_batch_size proportionally with slots_per_trial, it’s possible
that training performance is being bottlenecked by network communication or disk I/O.
To check if your training is bottlenecked by communication, we suggest setting
optimizations.aggregation_frequency in the experiment configuration to a very large number (e.g., 1000). This setting results in
communicating updates once every 1000 batches. Comparing throughput with an
aggregation_frequency of 1 vs. an aggregation_frequency of 1000 will demonstrate the
communication overhead. For more guidance on optimizing communication, see
Advanced Optimizations.
To check if your training is bottlenecked by I/O, we encourage users to experiment with using synthetic datasets. If you observe that I/O is a significant bottleneck, we suggest optimizing the data input pipeline to the model (e.g., copy training data to local SSDs).
Training Effectively with Large Batch Sizes#
To improve the performance of distributed training, we recommend using the largest possible
global_batch_size, setting it to be largest batch size that fits into a single GPU multiplied by
the number of slots. However, training with a large global_batch_size can have adverse effects
on the convergence (accuracy) of the model. The following techniques can be used for training with
large batch sizes:
Start with the
original learning rateused for a single GPU and gradually increase it tonumber of slots*original learning ratethroughout the first several epochs. For more details, see Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.Use custom optimizers designed for large batch training, such as RAdam, LARS, or LAMB. In our experience, RAdam has been particularly effective.
Applying these techniques often requires hyperparameter modifications. To help automate this process, use the Hyperparameter Tuning capabilities in Determined.