Quickstart for Model Developers#
This quickstart uses the MNIST dataset to demonstrate basic HPE Machine Learning Development Environment functionality and walks you through the steps needed to install HPE Machine Learning Development Environment, run training jobs, and visualize experiment results in your browser. Three examples show the scalability and enhanced functionality gained from simple configuration setting changes:
Train on a local, single CPU or GPU.
Run a distributed training job on multiple GPUs.
Use hyperparameter tuning.
An experiment is a training job that consists of one or more variations, or trials, on the same model. By calling HPE Machine Learning Development Environment API functions from your training loops, you automatically get metric frequency output, plots, and checkpointing for every experiment without writing extra code. You can use the WebUI to view model information, configuration settings, output logs, and training metrics for all of your experiments.
Each of these quickstart examples uses the same model code and example dataset, differing only in their configuration settings. For a list of all experiment configuration settings and more detailed information about each, visit the Experiment Configuration Reference.
Prerequisites#
Software#
HPE Machine Learning Development Environment agent and master nodes must be configured with the following operating systems:
Ubuntu 20.04 or later
Enterprise Linux (e.g., AlmaLinux, Oracle Linux, Red Hat Enterprise Linux, or Rocky Linux) 7 or higher
Windows Subsystem for Linux (WSL) 2 on Windows 10 version 1903 or higher, with a supported Linux distribution installed
macOS 10.13 or later
Agent nodes must have Docker installed.
To run jobs that use GPUs, you need NVIDIA drivers with a version of 384.81 or later installed on each agent. These drivers can be installed independently, but you don’t need to install the entire CUDA toolkit.
Hardware#
Master node:
At least 4 CPU cores. The master node does not require GPUs.
Intel/AMD x86 and Arm architectures are supported.
8GB RAM
200GB of free disk space.
Agent node:
At least 2 CPU cores.
Intel/AMD x86 and Arm architectures are supported.
If you are using GPUs, NVIDIA GPUs with compute capability 3.7 or greater are required: K80, P100, V100, A100, GTX 1080, GTX 1080 Ti, TITAN, or TITAN XP.
4GB RAM
50GB of free disk space.
Docker#
Install Docker to run containerized workloads. If you do not already have Docker installed, visit Install Docker to learn how to install and run Docker on Linux or macOS.
Get the Quickstart Training Examples#
Download and extract the files used in this quickstart to a local directory:
Download link:
mnist_pytorch.tgz.Extract the configuration and model files:
tar xzvf mnist_pytorch.tgz
You should see the following files in your local directory:
adaptive.yaml
const.yaml
data.py
distributed.yaml
layers.py
model_def.py
README.md
Description of the Configuration Files#
Each YAML-formatted configuration file corresponds an example experiment.
Configuration Filename |
Example Experiment |
|---|---|
|
Train a single model on a single GPU/CPU, with constant hyperparameter values. |
|
Train a single model using multiple, distributed GPUs. |
|
Perform a hyperparameter search using the HPE Machine Learning Development Environment adaptive hyperparameter tuning algorithm. |
Important
TensorFlow users must configure their environment image in this file before submitting an experiment.
environment: image: cpu: determinedai/tensorflow-ngc-dev:f17151a gpu: determinedai/tensorflow-ngc-dev:f17151a
Description of Model and Pipeline Definition Files#
Although the Python model and data pipeline definition files are not explained in this quickstart, you can review them to find out how to call the HPE Machine Learning Development Environment API from your own code:
Filename |
Experiment Type |
|---|---|
|
Model data loading and preparation code. |
|
Convolutional layers used by the model. |
|
Model definition and training/validation loops. |
After gaining basic familiarity with HPE Machine Learning Development Environment tools and operations, you can replace these files with your model data and code, and set configuration parameters for the kind of experiments you want to run.
Install HPE Machine Learning Development Environment and Run a Local Single CPU/GPU Training Job#
This exercise trains a single model for a fixed number of batches, using constant values for all hyperparameters on a single slot. A slot is a CPU or GPU computing device, which the master schedules to run.
To install the HPE Machine Learning Development Environment library and start a cluster locally, run the following commands:
pip install determined det deploy local cluster-up
If your local machine does not have a supported NVIDIA GPU, include the
no-gpuoption:pip install determined det deploy local cluster-up --no-gpu
In the
mnist_pytorchdirectory, create an experiment specifying theconst.yamlconfiguration file:det experiment create const.yaml .
The last dot (.) argument uploads all of the files in the current directory as the context directory for your model. HPE Machine Learning Development Environment copies the model context directory contents to the trial container working directory.
You should receive confirmation that the experiment is created:
Preparing files (.../mnist_pytorch) to send to master... 8.6KB and 7 files Created experiment 1
Tip
To automatically stream log messages for the first trial in an experiment to
stdout, specifying the configuration file and context directory, enter:det e create const.yaml . -f
The
-foption is the short form of--follow.Enter the cluster address in the browser address bar to view experiment progress in the WebUI. If you installed locally using the
det deploy localcommand, the URL ishttp://localhost:8080/. Accept the default username ofdeterminedand click Sign In. After signing in, create a strong password.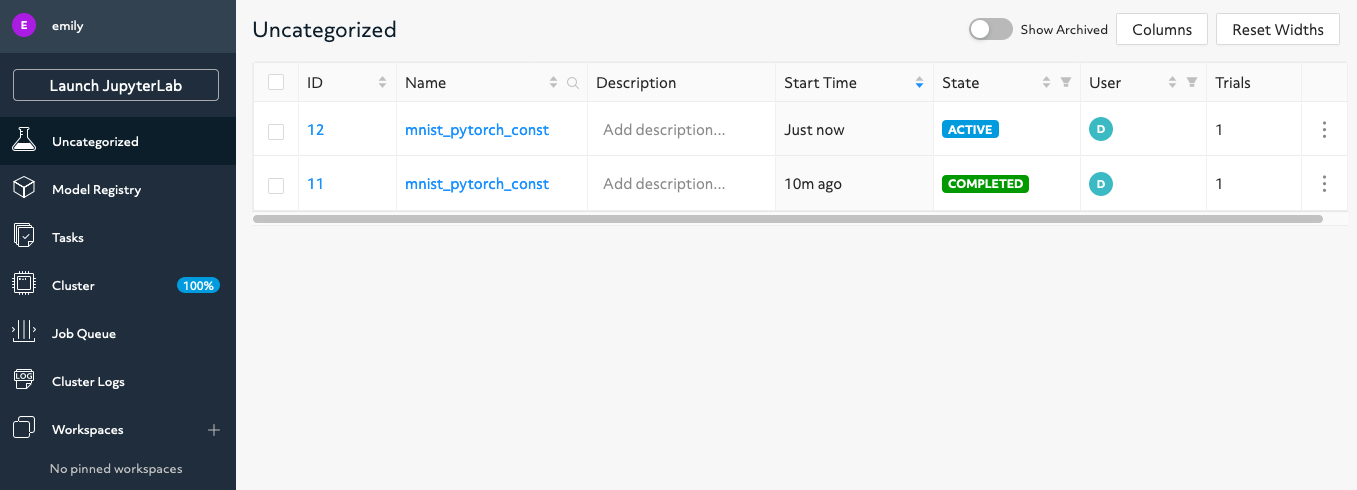
The figure shows all runs. Experiment 55989 has COMPLETED and experiment 55990 is still ACTIVE. Your experiment number and status can differ depending on how many times you run the examples.
While an experiment is in the ACTIVE, training state, click the experiment ID to see the Metrics graph update for your currently defined metrics:
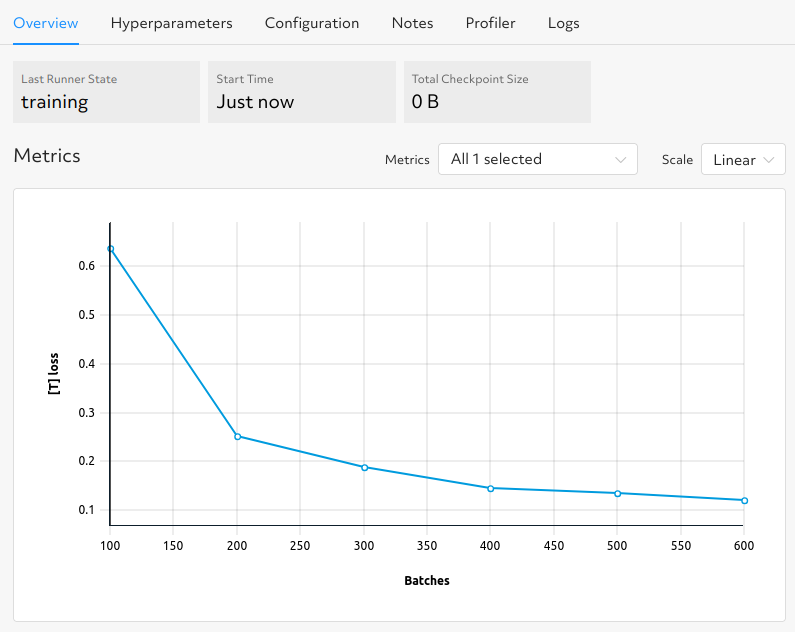
In this example, the graph displays the loss.
After the experiment completes, click the experiment name to view the trial page:
Now that you have a fundamental understanding of HPE Machine Learning Development Environment, follow the next example to learn how to scale to distributed training.
Run a Remote Distributed Training Job#
In the distributed training example, an HPE Machine Learning Development Environment cluster comprises a master and one or more agents. The master provides centralized management of the agent resources.
This example requires an HPE Machine Learning Development Environment cluster with multiple GPUs and, while it does not fully demonstrate the benefits of distributed training, it does show how to work with added hardware resources.
The distributed.yaml configuration file for this example is the same as the const.yaml file
in the previous example, except that a resources.slots_per_trial field is defined and set to a
value of 8:
resources:
slots_per_trial: 8
This is the number of available GPU resources. The slots_per_trial value must be divisible by
the number of GPUs per machine. You can change the value to match your hardware configuration.
To connect to an HPE Machine Learning Development Environment master running on a remote instance, set the remote IP address and port number in the
DET_MASTERenvironment variable:export DET_MASTER=<ipAddress>:8080
Create and run the experiment:
det experiment create distributed.yaml .
You can also use the
-moption to specify a remote master IP address:det -m http://<ipAddress>:8080 experiment create distributed.yaml .
To view the WebUI dashboard, enter the cluster address in your browser address bar, accept
determinedas the default username, and click Sign In. You’ll need to set a strong password.Click the experiment’s ID to view the experiment’s trial display. The loss curve is similar to the single-GPU experiment in the previous exercise but the time to complete the trial is reduced by about half.
Run a Hyperparameter Tuning Job#
This example demonstrates hyperparameter search. The example uses the adaptive.yaml
configuration file, which is similar to the const.yaml file in the first example but includes
additional hyperparameter settings:
hyperparameters:
global_batch_size: 64
learning_rate:
type: double
minval: .0001
maxval: 1.0
n_filters1:
type: int
minval: 8
maxval: 64
n_filters2:
type: int
minval: 8
maxval: 72
dropout1:
type: double
minval: .2
maxval: .8
dropout2:
type: double
minval: .2
maxval: .8
Hyperparameter searches involve multiple trials or model variations per experiment. The
The adaptive_asha search method and maximum number of trials, max_trials` are also specified:
searcher:
name: adaptive_asha
metric: validation_loss
smaller_is_better: true
max_trials: 16
time_metric: batch
max_time: 937
This example uses a fixed batch size and searches on dropout size, filters, and learning rate. The
max_trials setting of 16 indicates how many model configurations to explore.
Create and run the experiment:
det experiment create adaptive.yaml .
To view the WebUI dashboard, enter your cluster address in the browser address bar, accept the default username of
determined, and click Sign In. After signing in, create a strong password.The experiment can take some time to complete. You can monitor progress in the WebUI Dashboard by clicking the Experiment name. Notice that more trials have started:
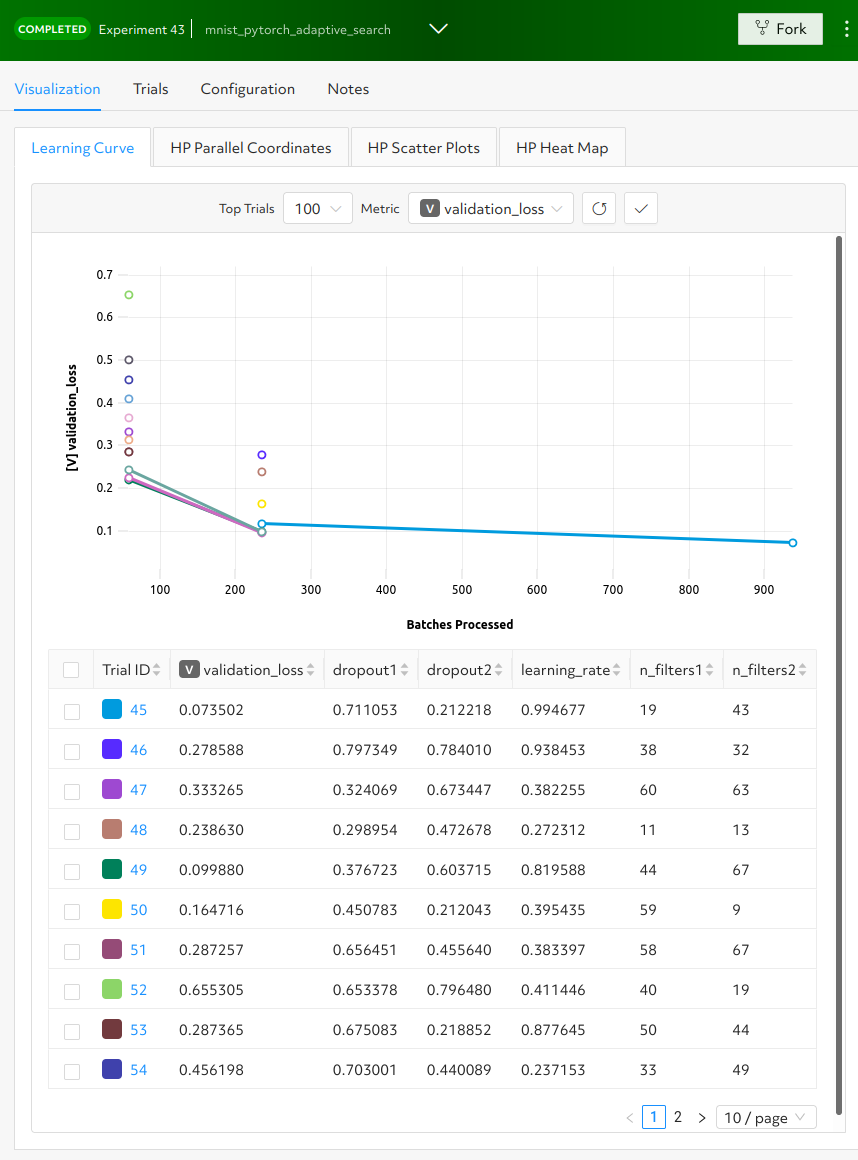
HPE Machine Learning Development Environment runs the number of
max_trialstrials and automatically starts new trials as resources become available. For 16 trials, it should take about 10 minutes to train with at least one trial performing at about 98 percent validation accuracy. The hyperparameter search halts poorly performing trials.
Learn More#
For installation guides including how to quickly install HPE Machine Learning Development Environment locally, visit Install and Set Up HPE Machine Learning Development Environment.
The Core API User Guide walks you through adapting your existing model code to HPE Machine Learning Development Environment and uses the PyTorch MNIST model.
The Examples contain machine learning models that have been converted to the HPE Machine Learning Development Environment APIs. Each example includes a model definition and one or more experiment configuration files, and instructions on how to run the example.
To learn more about the hyperparameter search algorithm, visit Hyperparameter Tuning.
For faster, less structured ways to run an HPE Machine Learning Development Environment cluster without writing a model, consult the following resources: